
同类型软件
Stable Diffusion中文版是一款实用性极强的AI图像生成神器,这款软件操作简单、功能齐全、完成度极高,用户在这里只需要将没有创作完成的图片进行导入操作,然后系统便会自动生成完整的图片内容,这样就能够为用户的创作过程带来极大的便利性。另外,该软件采用了全新的算法,可以有效的强化了输出效果。
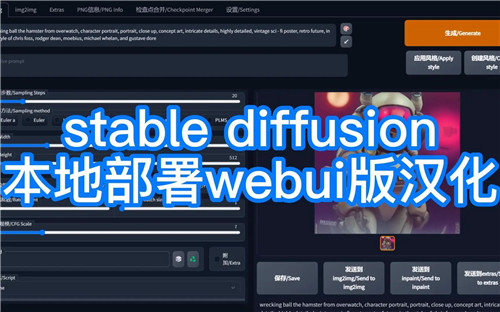
Stable Diffusion中文版完全免费使用并且还去除了繁琐的本地部署步骤,用户在这里可以直接生成各种类型的图像,这样就能够很好的满足了不同用户的使用需求。该软件还能够为用户提供非常丰富的参数,用户可以根据自己的需求进行调整,相信这样就能够使得图片成品更加符合自己的预期。
首先,从名字Stable Diffusion就可以看出,这个主要采用的扩散模型(Diffusion Model)。
简单来说,扩散模型就是去噪自编码器的连续应用,逐步生成图像的过程。
一般所言的扩散,是反复在图像中添加小的、随机的噪声。而扩散模型则与这个过程相反——将噪声生成高清图像。训练的神经网络通常为U-net。
不过因为模型是直接在像素空间运行,导致扩散模型的训练、计算成本十分昂贵。
基于这样的背景下,Stable Diffusion主要分两步进行。
首先,使用编码器将图像x压缩为较低维的潜在空间表示z(x)。
其中上下文(Context)y,即输入的文本提示,用来指导x的去噪。
它与时间步长t一起,以简单连接和交叉两种方式,注入到潜在空间表示中去。
随后在z(x)基础上进行扩散与去噪。换言之, 就是模型并不直接在图像上进行计算,从而减少了训练时间、效果更好。
值得一提的是,Stable DIffusion的上下文机制非常灵活,y不光可以是图像标签,就是蒙版图像、场景分割、空间布局,也能够相应完成。
建立一个文件夹,用于存放本地文件。
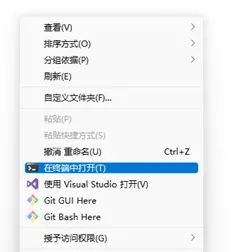
右键页面空白处,在终端中打开。
执行指令 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git。
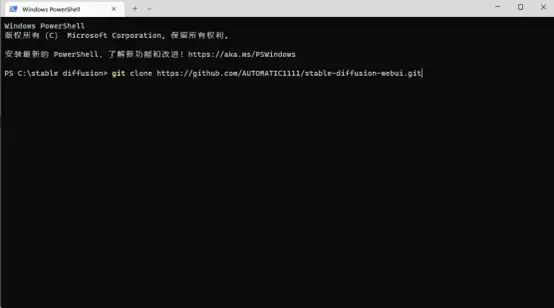
执行完后就像这样。

然后我们就可以关掉这个页面了,回到刚才新建的文件夹,里面出现了我们刚clone的文件。
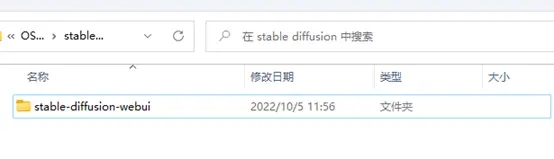
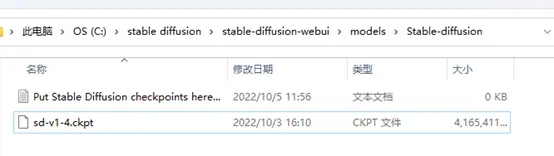
把我们下载好的模型文件,我这里使用的是stable-diffusion-v1-4(sd-v1-4.ckpt)丢到stable-diffusion-webui\models\Stable-diffusion这个文件夹下。
像这样。
然后我们回到stable-diffusion-webui文件夹,找到webui.bat,双击打开运行。
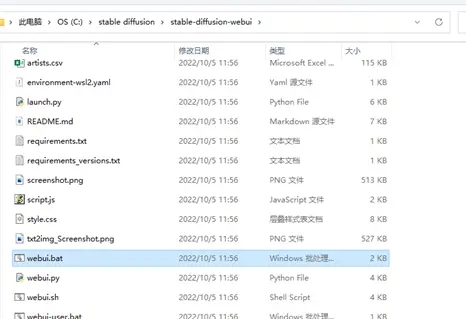
然后就是漫长的等待,直到它运行完成。
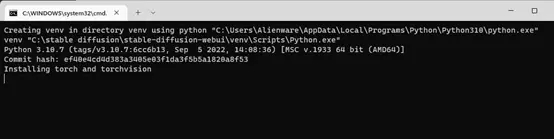
中间可能会因为网络问题报错,重新运行webui.bat多试几遍,(这段可能会劝退很多人)实在懒得折腾就回到上面去用GUI版的。
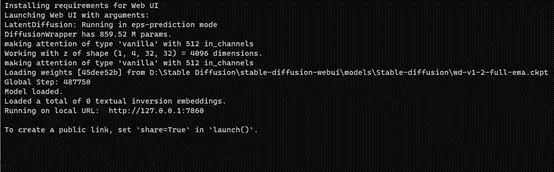
部署完成后会是这样,下面有一个URL,我们把它复制到浏览器中打开。
(这个窗口不要关)
像这样。
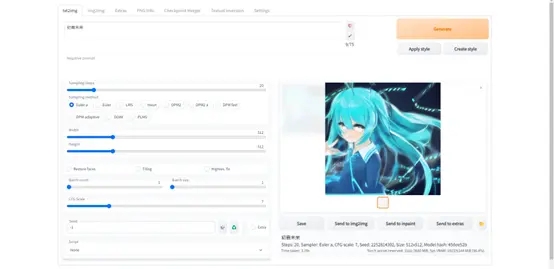
输几个关键词试一下。
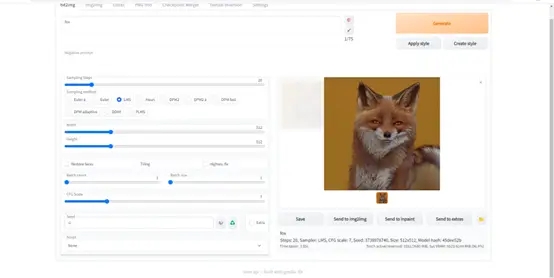
到此,本地部署就完成了,如果有切换模型的需求,只需把原来的模型删掉换上新的模型即可。
Q1:为什么我们要本地部署?
A1:stable diffusion本地部署的运行完全基于用户的本地电脑,给使用者带来极大的自由度,比如可以使用不同的微调模型,同时也能有效避免你的创作作品泄露。
Q2:本地部署的stable diffusion WEBUI和在线版有什么不同?
A2:stable diffusion WEBUI是典型的开源集成,一个月内迭代几十次,增加一大堆功能。标准化的本地部署能让你体验到这个和创新同步的过程。这是很多懒人版直接解压版本(无法用git升级)和网页版无法带给你的。
重要:在本地部署之前,确保你所使用的电脑满足所需的依赖项。
一般来说,内存不应低于16G.硬盘可用空间不小于50G。
要求一张显存大于4GB(最好高于6GB,建议8GB以上)的高性能显卡,我们的建议是GPU不低于Nvidia 10系,因为N卡在专业应用生态上一枝独秀,因此我们推荐NVidia卡(强烈推荐)。
如果你使用AMD卡,则需要安装ROCM(仅能在LINUX环境安装,在WIN10环境无法使用),可参考的资料很少,会比较(very)麻烦。因未曾测试过,本艺术家暂无法提供技术支持。
由于stable-diffusion是开源的,为它提供整合的有非常多的版本。选择好的版本就变得非常重要。
热门关键词
分类列表
精品推荐









